بکاپ گیری از اطلاعات
یکی از اساسی ترین مسایل برای فهم پشتیبان گیری (backup) و بازیابی (recovery) ، مفهومِ سطوح backup است و اینکه هر یک از این سطوح چه معنایی دارند.
فقدانِ درک صحیح از اینکه این سطوح چه هستند و چگونه به کار گرفته می شوند، منجر شده است که سازمان ها تجربه ناخوشایندی از پهنای باند و فضای ذخیره سازی به هدر رفته ای داشته باشند که جهت از دست نرفتن داده های مهم در بکاپ گیری از اطلاعات به آنها تحمیل می شود. همچنین درک این مفاهیم به هنگام انتخاب محصولات یا خدمات حفاظت از اطلاعات بسیار ضروری است.
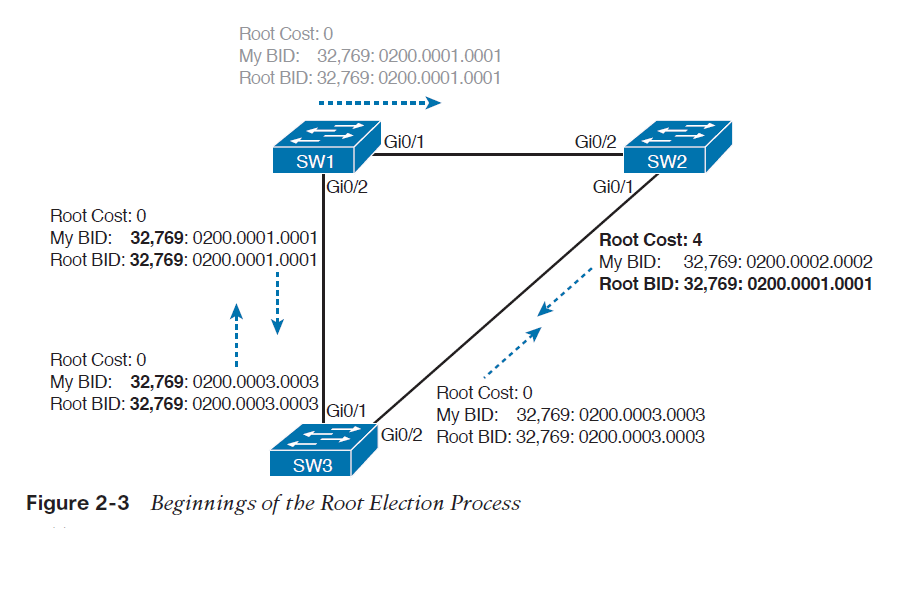
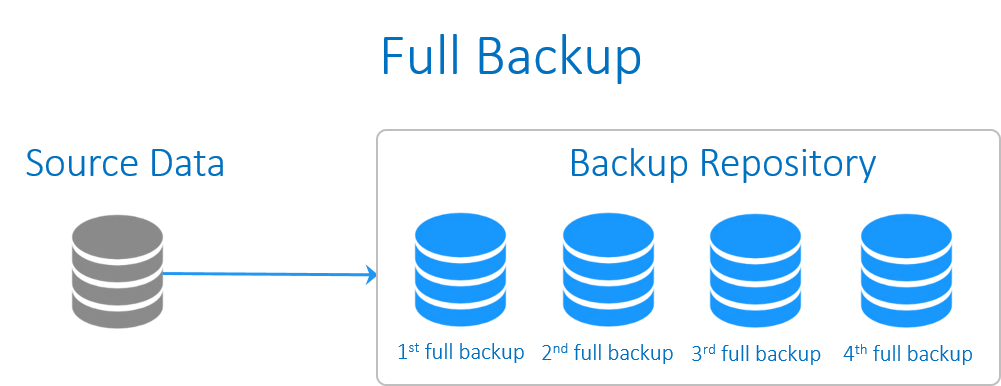
Full backup
پشتیبان گیریِ کامل، شامل همه داده های کل سیستم می شود. بکاپ کامل از Windows system ، باید کپی هر یک از فایل ها بر روی هر درایو از ماشین یا VM را در برگیرد.
تنها چیزی که در پشتیبان گیری کامل حذف می شود، فایل هایی هستند که از طریق پیکربندی مستثنا می شوند. به طور مثال، اکثر ادمین های سیستم تصمیم می گیرند که دایرکتوری هایی را که در طول بازگردانی ارزشی ندارند (به طور مثال، /boot یا /dev) یا دایرکتوری های شامل فایل های موقتی (به طور مثال، C:\Windows\TEMP در ویندوز، یا /tmp در لینوکس) حذف شوند.
در مورد اینکه فرآیند بکاپ گیری از اطلاعات شامل چه فایل هایی باید شود، دو رویکرد وجود دارد: از همه چیز بکاپ بگیرید و چیزهایی را که می دانید به آنها نیاز ندارید را حذف کنید، یا اینکه تنها چیزی را که می خواهید از آن بکاپ بگیرید، انتخاب کنید. اولین رویکرد گزینه ای امن تر است و رویکرد دوم نیز منجر به صرفه جویی در فضای سیستم بکاپ گیری از اطلاعات شما خواهد شد. برخی معتقدند که بکاپ گیری از فایل های اپلیکیشن همچون دایرکتوری های شامل SQL Server یا Oracle ، بیهوده است و به سادگی در طول فرآیند بازگردانی، اپلیکیشن را دوباره بارگذاری می کنند. مشکل رویکرد اخیر این است که احتمال دارد شخصی داده ای ارزشمند را در یک دایرکتوری قرار دهد که برای پشتیبان گیری انتخاب نشده است. به فرض اگر شما تنها دایرکتوریِ home/ یا D:\Data را برای پشتیبان گیری برگزینید، چگونه سیستمِ بکاپ تشخیص خواهد داد که شخصی اطلاعاتی مهم را در دیگر دایرکتورها ذخیره کرده است؟ به همین دلیل، با وجود اینکه رویکرد اول فضای زیادتری را اشغال می کند، پشتیبان گیری از همه چیز روشی امن تر می باشد و تنها فایلهایی که نیازی ندارید، حذف می شوند. البته اگر شما یک محیطِ به شدت کنترل شده داشته باشید که در آن همه داده ها در مکانی مشخص بارگذاری شده باشند و راهکار هماهنگ شده ی مناسبی برای جابجایی سیستم عامل و اپلیکیشن ها در فرآیند بازگردانی داشته باشید، استفاده از راهکار دوم برایتان موثر خواهد بود.
از آنجایی که حجم عظیمی از داده ها باید کپی شوند، در این فرآیند زمان بسیاری صرف خواهد شد (در مقایسه با انواع دیگر از روش های بکاپ گیری از اطلاعات ، این روش 10 برابر زمان بیشتری را صرف می کند). در نتیجه در هر نوبتِ پشتیبان گیری، بارکاری قابل ملاحظه ای به شبکه تحمیل می شود و با عملیات روتینِ شبکه شما تداخل پیدا می کند. همچنین بکاپ گیری از اطلاعات به طور کامل حجم بالایی از فضای ذخیره سازی را نیز اشغال می کند.
به همین دلیل است که بکاپ گیری از اطلاعات به طور کامل تنها به صورت دوره ای گرفته خواهد شد و آن را با انواع دیگر بکاپ ترکیب می کنند.
فواید بکاپ گیری از اطلاعات به طور کامل:
- ریکاوری سریعِ داده ها به هنگام رخدادِ یک disaster
- مدیریت بهتر ذخیره سازی، از آنجایی که تمام مجموعه داده ها در یک فایل بکاپِ واحد ذخیره می شوند
معایب بکاپ گیری از اطلاعات به طور کامل:
با وجود اینکه بکاپ گیری از اطلاعات به طور کامل، مزیت های بالا را برای شما به ارمغان می آورد اما شامل نقاط ضعف بسیاری نیز هست:
- اجرای بکاپِ کامل، زمان بسیاری زیادی را به خود اختصاص می دهد
- شما نیاز به یک ذخیره ساز با ظرفیت بسیار بالا خواهید داشت تا بتواند همه بکاپ های شما را دربر گیرد
- از آنجایی که هر فایلِ full backup شامل کل مجموعه داده های شماست (که اغلب محرمانه هستند)، اگر این داده ها به دسترسی شخصی فاقدِ صلاحیت برسند، کسب و کار شما دچار مخاطره می شود. هر چند اگر راهکار بکاپِ شما از ویژگی data protection پشتیبانی نماید، می توان از این خطرات پیشگیری نمود.
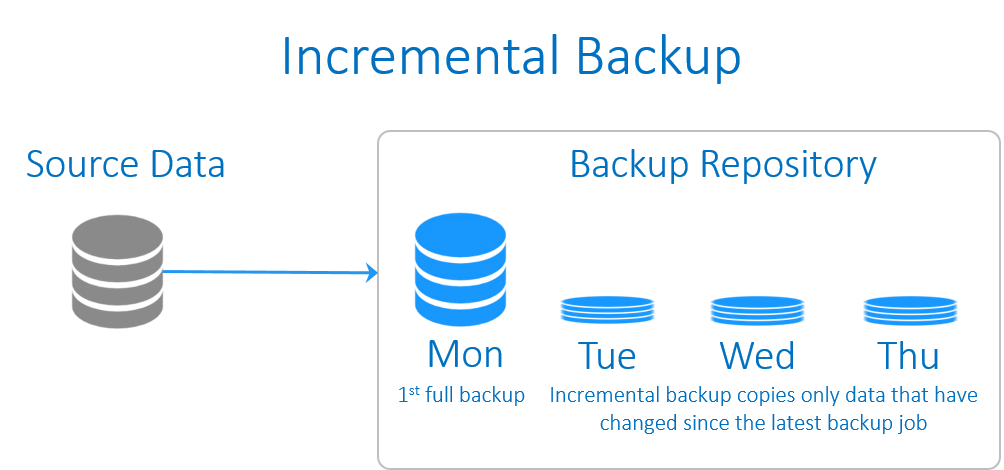
incremental backup (بکاپ افزایشی)
بکاپِ افزایشی معمولا از داده هایی پشتیبان می گیرد که از زمان آخرین بکاپِ گرفته شده (هر نوعی از بکاپ که باشد)، تغییری روی آنها صورت گرفته باشد. گرفتن یک بکاپِ کاملِ اولیه از پیش شرط های ایجادِ بکاپِ افزایشی است. و بسته به سیاست های ذخیره سازیِ بکاپ، پس از یک دوره زمانی معین به یک full backup جدید برای تکرار این سیکل نیاز است.
برخی از این نوع بکاپ ها، بکاپ های file-based هستند به این معنا که از همه فایلهایی که نسبت به آخرین زمان بکاپ تغییر کرده باشند، بکاپ تهیه می شود. در حالی که ما به روش های مختلف می کوشیم تا تاثیر I/O ناشی از بکاپها بر روی سرور (به خصوص به هنگام پشتیبان گیری از VM ها) را کاهش دهیم، در این شیوه بکاپ گیری از اطلاعات با چالشی در این مورد مواجه خواهیم شد. چرا که پشتیبان گیری از یک فایل 10GB که تنها 1 MB از آن تغییر کرده است، چندان کارآمد نیست.
به دلیل ناکارآمدی در شیوه file-based، اکثر کمپانی ها به سمت بکاپ افزایشیِ block-based رفته اند که در آن تنها از بلاک های تغییر یافته، بکاپ گرفته می شود. رایجترین روش برای انجام آن هنگامی است که از محصولات نرم افزاری بکاپ تهیه می شود، به طور مثال از VMware یا Hyper-V با استفاده از API هر یک از آنها، می توان پشتیبان تهیه نمود. هر App یک API مناسب خود را اعلام می کند که بکاپ افزایشیِ block-based را انجام می دهد.
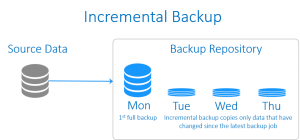
بکاپ افزایشی از سرعت بالایی برخوردار است و در مقایسه با full backup، به فضای ذخیره سازیِ بسیار کمتری نیاز دارد. اما از آنجایی که در این شیوه به بازگردانیِ آخرین بکاپِ کامل و علاوه بر آن کل زنجیره بکاپ های افزایشی نیاز است، فرآیند ریکاوریِ آن مدت زمان بیشتری به طول می انجامد. اگر یکی از بکاپ های افزایشی در این زنجیره بکاپ از دست برود یا صدمه ببیند، ریکاوری کامل آن غیر ممکن خواهد شد.
فواید بکاپ افزایشی:
- از آنجایی که تنها از داده های افزوده شده بکاپ تهیه می شود، فرآیند بکاپ گیری از اطلاعات سرعت بسیار بالایی دارد
- به فضای ذخیره سازی کمتری نیاز است
- هر کدام از این بکاپ های افزایشی یک نقطه بازیابی مجزا هستند
معایب بکاپ افزایشی:
- هنگامی که شما نیاز داشته باشید، هم بکاپ کامل و هم همه ی بکاپ های افزایشی متوالی را بازگردانید، سرعت بازگردانیِ کامل داده ها پایین است
- بازگردانیِ موفق داده ها به عدم نقص در تمامیِ بکاپ های افزایشی موجود در زنجیره وابسته است
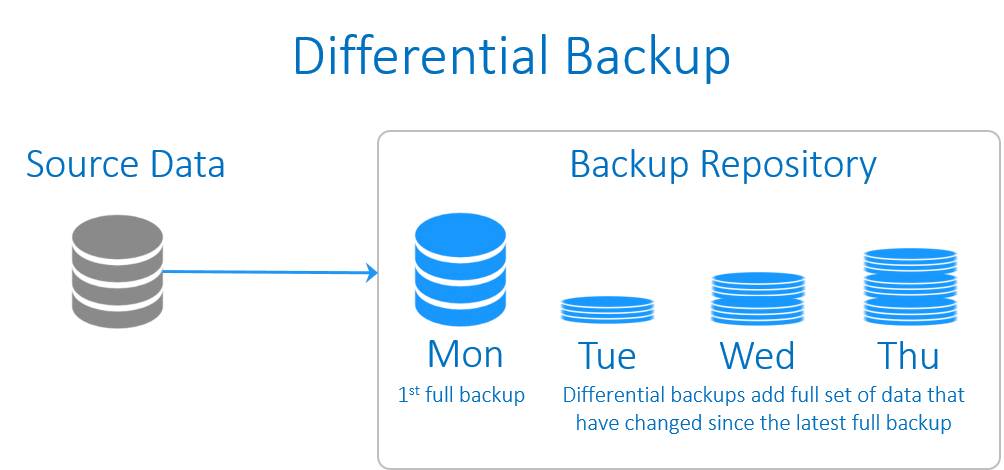
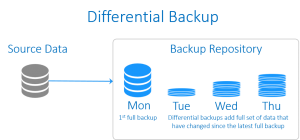
Differential backup (بکاپ تفاضلی)
Differential backup راهکاری بینابینِ بکاپ افزایشی و بکاپ کامل است. همچون بکاپ افزایشی، در اینجا نیز نقطه آغاز بکاپ گیری از اطلاعات وجود یک بکاپ کامل اولیه است. سپس از همه داده ها که از زمان آخرین بکاپ کامل (full backup) تغییر کرده باشند، بکاپ گرفته می شود. در مقایسه با بکاپ های افزایشی، differential backup اکثر داده هایی که در بکاپ های اخیر تغییر کرده اند را ذخیره نمی کند، تنها داده هایی ذخیره می شوند که نسبت به بکاپ کامل اولیه تغییر کرده اند. بنابراین بکاپ کامل، نقطه مبنا برای بکاپ گیری متوالی است. در نتیجه بکاپ differential در مقایسه با بکاپ افزایشی، سرعت بازگردانی داده را افزایش می دهد چرا که تنها به دو قطعه بکاپ اولیه و آخرین بکاپِ differential نیاز است. این نوع از بکاپ گیری از اطلاعات در زمان استفاده از درایوهای tape رواج بسیاری داشت، چرا که تعداد tape های مورد نیاز برای بازگردانی را کاهش می داد. بازگردانی (restore) نیاز به آخرین بکاپ کامل در کنار آخرین differential backup و incremental backup دارد.
ویژگی ها
از لحاظِ سرعتِ پشتیبان گیری/بازگردانی، بکاپ differential به عنوانِ راهکاری است که در میانِ دو راهکار بکاپِ کامل و بکاپ افزایشی قرار می گیرد:
- عملیات بکاپ گیری از اطلاعات در آن کندتر از بکاپ افزایشی اما سریعتر از بکاپ کامل است
- عملیات بازگردانیِ آن، آهسته تر از بکاپ کامل اما سریع تر از بکاپ افزایشی است
فضای ذخیره سازی لازم برای بکاپِ differential، حداقل در یک دوره مشخص، کمتر از فضای لازم برای بکاپِ کامل و بیشتر از فضای مورد نیاز برای بکاپ افزایشی است.
Mirror backup
این راهکار مشابه با بکاپ گیری از اطلاعات به طور کامل است. این نوع بکاپ گیری از اطلاعات، کپی دقیقی از مجموعه داده ها ایجاد می کند با این تفاوت که بدون ردیابیِ نسخه های مختلفِ فایل ها، تنها آخرین نسخه از داده در بکاپ ذخیره می شود.
بکاپِ Mirror ، فرآیند ایجاد کپی مستقیمی از فایل ها و فولدرهای انتخاب شده، در زمانی معین است. از آنجایی که فایل ها و فولدرها بدون هیچ گونه فشرده سازی در مقصد کپی می شود، سریع ترین انواع روش های بکاپ گیری از اطلاعات است. با وجود سرعت افزایش یافته در آن، نقاط ضعفی را نیز به همراه خواهد داشت: به فضای ذخیره سازی وسیعتری نیاز دارد و نمی تواند از طریق رمز عبور محافظت شود.
در این نوع از بکاپ گیری، هنگامی که فایل های بی کاربرد حذف می شوند، از روی بکاپِ mirror نیز حذف خواهند شد. بسیاری از خدماتِ بکاپ ، بکاپِ mirror را با حداقل 30 روز فرصت برای حذف پیشنهاد می کنند. به این معناست که به هنگام حذف یک فایل از منبع، آن فایل حداقل 30 روز بر روی storage server نگهداری می شود.
ویژگی ها
امتیازی که بکاپِ mirror در اختیار شما می گذارد، بکاپی درست است که شامل فایل های منسوخ شده و قدیمی نمی شود.
و اما معایب آن زمانی خود را نشان خواهد داد که فایل ها به صورت تصادفی یا به واسطه ویروس ها از منبع حذف شده باشند.
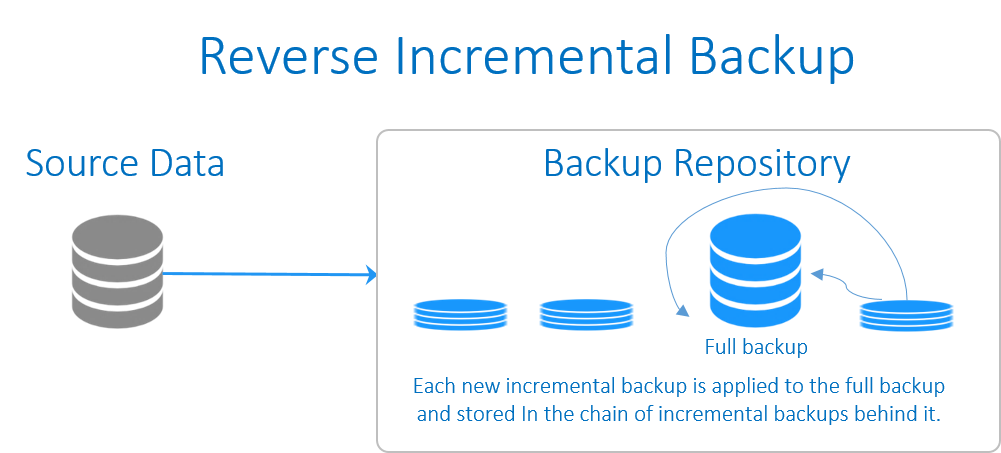
Reverse Incremental Backup (بکاپ افزایشی معکوس)
در این نوع بکاپ گیری از اطلاعات نیز برای شروع به یک بکاپ کامل اولیه نیاز است. پس از ایجاد بکاپِ کامل اولیه، هر بکاپ افزایشیِ موفق تغییرات را به نسخه پیشین اعمال می کند که در نتیجه آن در هر زمان یک بکاپ کاملِ جدید (به صورت مصنوعی) ایجاد می شود. در حالی که کماکان توانایی بازگشت به نسخه های پیشین وجود دارد. هر یک از بکاپ های افزایشیِ اعمال شده به بکاپ کامل، نیز ذخیره می شوند که در زنجیره ای از بکاپ ها، به طور مستمر در پشت سرِ بکاپ کاملِ به روز شده، در جریان هستند.
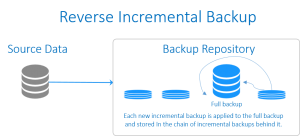
امتیاز اصلی در این نوع از بکاپ گیری فرآیند بازیابی کارآمدترِ آن است، چرا که بخش زیادی از جدیدترین نسخه های داده به بکاپ کامل اولیه اضافه می شود و نیازی ندارید بکاپ های افزایشی را در طول بازیابی بکار ببندید. در گیف زیر فرآیند اجرای این نوع بکاپ نشان داده شده است.

Smart backup (بکاپ هوشمند)
بکاپ هوشمند، ترکیبی از بکاپ های کامل، افزایشی و تفاضلی است. بسته به هدفی که در بکاپ گیری از اطلاعات در نظر دارید و همچنین فضای ذخیره سازیِ در دسترس، بکاپ هوشمند می تواند راهکاری کارآمد را ارائه دهد. جدول زیر ایده ای در رابطه با چگونگی کارکرد این نوع بکاپ، در اختیار شما می گذارد.
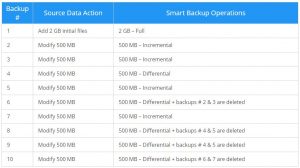
با استفاده از بکاپ هوشمند، همیشه می توانید تضمین نمایید که فضای ذخیره سازیِ کافی برای بکاپ های خود در اختیار دارید.
Continuous Data Protection (محافظت مستمر از داده)
بر خلاف بکاپ های دیگر که به صورت دوره ای انجام می شوند، CDP از هر تغییری در مجموعه داده های منبع log تهیه می کند که از سویی مشابه با بکاپِ mirror است. اختلاف CDP با mirror در این است که log مربوط به تغییرات برای بازیابیِ نسخه های قدیمی تر از داده می تواند بازیابی شود.
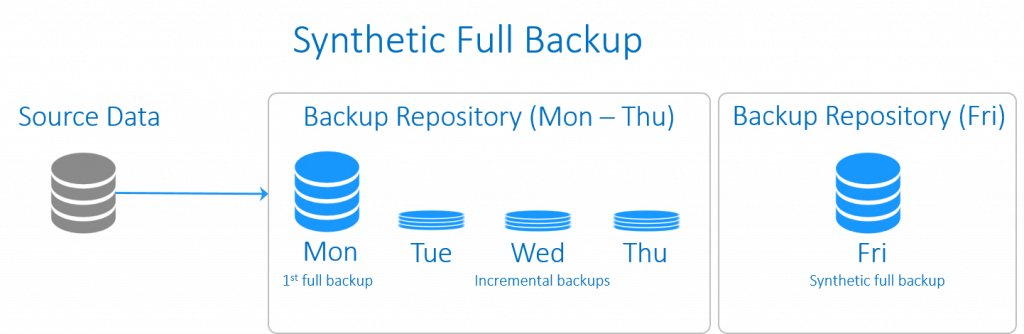
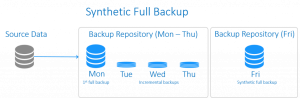
Synthetic Full Backup (بکاپ کامل ساختگی)
این نوع از بکاپ شباهت های بسیاری با بکاپ افزایشی معکوس دارد. اختلافِ آنها در چگونگی مدیریت داده هاست. بکاپ کامل مصنوعی با اجرای بکاپ کاملِ مرسوم آغاز می شود که در ادامه مجموعه ای از بکاپ ها افزایشی را در پی دارد. در زمانی معین، بکاپ های افزایشی هماهنگ می شوند و به بکاپ کاملِ موجود اعمال می شوند تا بکاپ کاملی را به طور مصنوعی و به عنوان یک نقطه شروعِ جدید ایجاد نمایند.
بکاپ کاملِ ساختگی، تمامی امتیازات یک بکاپ کامل را دارد، در حالی که زمان و فضای ذخیره سازیِ کمتری را صرف می کند.
از جمله مزایای بهره وری از بکاپ کامل ساختگی عبارتند از:
- عملیات بازیابی و بکاپ گیریِ سریع
- مدیریتِ بهترِ ذخیره ساز
- نیاز کمتر به فضای ذخیره سازی
- یارهای کاریِ کمتر در شبکه
Forever-Incremental Backup
این راهکار با بکاپ افزایشی عادی متفاوت است. همچون اکثر راهکارهای پیشین برای شروع به یک بکاپ کامل اولیه به عنوان یک نقطه مرجع برای ردگیری تغییرات نیاز دارد. از آن لحظه، تنها بکاپ های افزایشی بدون هیچ گونه بکاپ کاملِ دوره ای ایجاد می شوند.
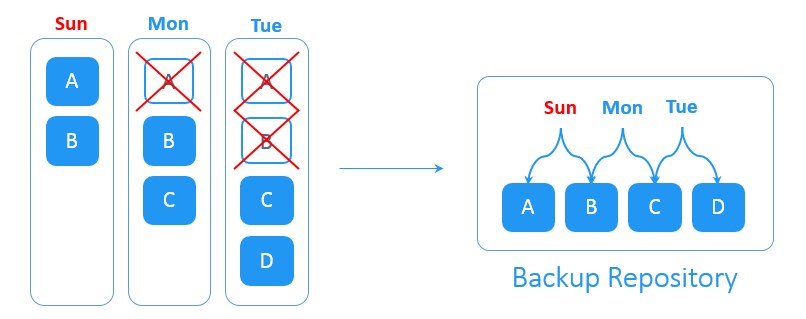
فرض کنید که شما بکاپ کامل را در روز شنبه ایجاد کردید. با شروع روز بعد، بکاپ های افزایشی به صورت روزانه ایجاد می شوند. در روز یکشنبه دو بلوک جدیدِ A و B در مجموعه داده های منبع ایجاد شده اند. در روز دوشنبه بلوک A حذف و بلوکِ جدید C بر روی منبع ایجاد شده است. در روز سه شنبه بلوک B حذف و بلوک جدید D ایجاد شده است. سیستمِ forever-incremental backup تمامیِ تغییرات روزانه را پیگیری می کند. حذف بلوک های داده تکراری تا فضای ذخیره سازی مورد نیاز برای بکاپ را کاهش دهد.
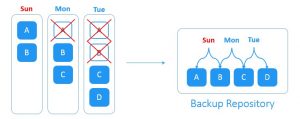
یا توجه به سیاست های ویژه در زمینه نگهداری بکاپ ها، پس از ایجادِ مجموعه ای از بکاپ های افزایشی، نقاط بکاپ گیری و بازیابیِ منقضی شده حذف می شوند تا فضای ذخیره سازیِ اشغال شده در backup repository آزاد شود.
امتیازاتی که روش بکاپ گیریِ forever-incremental نصیب شما خواهد کرد نیز مشابه با روشِ بکاپ کامل ساختگی است.
جمع بندی
در حقیقت راهکار بکاپ گیری از اطلاعات خوب یا بد وجود ندارد. باید در نظر بگیرید که چه نوعی از بکاپ گیری برای شما بهترین است و نیازهای ویژه ی سازمانِ شما را بر مبنای سیاست های محافظت از داده، ذخیره سازِ موجود، منابع، پهنای باند شبکه، نواحی داده ای مهم و …. برآورده می سازد.
توجه: برای وضوح تصاویر بر روی آن ها کلیک کنید.
منبع : http://irdatacenter.blogroz.ir/